
Uniprot clustering benchmark
Input was the Uniprot protein database including both Swiss-Prot and TrEMBL, version June_2013. This is a 18 Gb FASTA file containing 43,362,837 (43.4M) amino acid sequences.
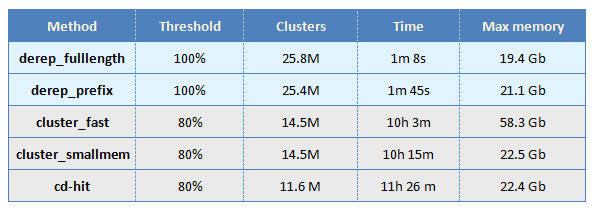
USEARCH clustering was tested using the derep_fulllength, derep_prefix, cluster_fast and cluster_smallmem commands in USEARCH v7.0.1090, 64-bit build for Linux.
CD-HIT clustering was tested using v4.6.
See also: hardware configuration.
Command lines
usearch -derep_fulllength uniprot.fa -minseqlength 32 -threads 6 -output full.fa
usearch -derep_prefix uniprot.fa -minseqlength 32 -threads 6 -output prefix.fa
usearch -cluster_fast uniprot.fa -minseqlength 32 -id 0.8 -threads 6 -centroids fast80.fa
usearch -cluster_smallmem uniprot.fa -minseqlength 32 -id 0.8 -centroids small0.fa
cd-hit -i uniprot.fa -M 0 -T 6 -n 5 -c 0.8 -o uniprot80