See also
Taxonomy benchmark home
Defining "accuracy" of a taxonomy classifier
Taxonomy classification errors
Taxonomy prediction confidence measure
UTAX algorithm
Case study: RDP predicts genus, UTAX predicts phylum
Validating SSU taxonomy classifiers is a challenging problem.
Classifiers use different taxonomies which cannot be directly compared, e.g. Bergey, NCBI and Greengenes. Also, classifiers vary in the methods they use for reporting confidence in the prediction. GAST does not provide any confidence score. The RDP Naive Bayesian Classifier (here abbreviated to RDP, not to be confused with the Ribosomal Database Project itself) reports a bootstrap confidence score while UTAX reports an estimated probability that the prediction is correct. How can such methods be fairly compared?
Absolute performance (i.e., sensitivity and error rate on real data) cannot be measured because it will be highly dependent on the composition of the community (human gut vs. soil vs. buried Antarctic lake) and how well represented the community is in the reference set. However, it is possible to measure the relative performance of different classification algorithms by dividing a gold standard reference set into training and test sets and using the training set as a reference for the stand-alone programs. For my benchmark tests, I used the RDP 16S training data and the UNITE database as trusted references.
Classification is easy at high identity
If the query sequence matches a reference sequence with high identity, then
it probably has the same taxonomy, except perhaps at the lowest levels (say,
species or strain). All
classifiers are based in some way on sequence identity, and all will give good
results when there is high identity. The real challenge for a classifier is how
to handle sequences with lower identity. For example, suppose you have a 87%
match to a 16S sequence. Should it be assigned to the same genus, family or
order? How can we measure the accuracy of a classifier when presented with this
type of challenge? See here for a case study where the
top hit has 87% identity.
Reference databases have poor coverage
With microbial marker genes such as 16S and ITS only a
small fraction of species have taxonomic names and known sequences.
This means that classifiers should be designed to give no prediction or a low
confidence score when similarity with the reference set is low, indicating a
novel sequence. However, many classifiers implicitly assume that the reference
database contains most or all taxa, and the RDP validation also assumes this
(next section).
The RDP "leave-one-out" method
The RDP classifier papers use
leave-one-out. which works as follows. They take their training database (D) and
remove one sequence (call it Q, the query sequence) leaving a reduced database D'. They re-train
their classifier using D' and test whether Q is correctly classified. They
repeat this for all sequences in the database. Each level is tested (genus, family...)
to measure "accuracy", defined as the percentage of correctly classified
sequences.
The RDP validation method grossly over-states accuracy
The RDP leave-one-out method is highly
misleading. RDP classifies to genus level (not to species), and the average number of reference sequences per genus in their training
set is five, so doing leave-one-out effectively asks the question "how well can
you classify a novel sequence if four other members of the genus are present in
the reference database". This reasonable only if you believe that most genera
in your sample are present in your reference set. It does not test how well the classifier performs when challenged with
novel taxa at any level.
Also, RDP uses zero as the bootstrap confidence cutoff for calculating accuracy. Yes, zero! So "accuracy" by their definition is really the maximum possible sensitivity to known taxa. In practice, a cutoff of 50% or 80% is typically used for sequences obtained from NGS reads. With this cutoff, sensitivity is lower and the false-positive rate on novel sequences is high. See also a case study where RDP predicts genus while UTAX predicts only phylum.
At higher levels, this approach is just nonsense. The RDP papers claims e.g. 98% sensitivity at family level, but that's simply not informative when the genus is still present for 8095 / 8978 = 90% of the sequences after deleting the test sequence.
How to measure classification accuracy
What we should care about to understand
classification accuracy at higher levels is how well the classifier performs at
lower identities when it has to climb the tree. Let's say we want to measure
family level accuracy. If the genus is present, it's too easy and that's not
what we're trying test. I use the following method (see figure at bottom of
this page).
Split the reference sequences into a query set (Q) and database set (D) so that all families in Q are present in D, but the same genus is never present in both. (Singleton families are discarded). To get a correct prediction with this data, the classifier must identify the family by matching to a different genus in the same family. Since the family is always present in D, we can use this to measure family-level sensitivity: it's the fraction of Q sequences that are successfully assigned to the correct family.
This test will give some errors, but we're still going too easy on the classifier. We also want to know the error rate at family level when the family is NOT present. To do this, we split the database differently so that the same family is never present, but the level above (order, in this case) is always present. We want the order present so that there are sequences which are as close as possible without being in the same family. This is the hardest case for a classifier to deal with. Now we're asking how often does the classifier reports family when it should be reporting order.
So this is my validation protocol: For each taxonomic level (genus, family... phylum), make two Query-Database pairs by splitting your trusted reference set. In one pair (the "possible" pair), at least one example is present in the database so the classification is possible. This measures sensitivity and the error rate of misclassifying to a different taxon. The second Q-D pair ("impossible") has no examples of the taxon, so assignments at the given level are always errors. This measures the rate of overclassification errors.
Validating confidence scores
Informatics prediction algorithms should give a
score indicating confidence that the prediction is correct. A
score allows the user to set a cutoff to achieve a trade-off between sensitivity
and error rate. Reporting a p-value is ideal, because this allows the
user to estimate the error rate for a given cutoff. If a p-value cannot be
calculated, then a confidence score is the next best thing because this still
allows the user to set a cutoff. However, with a score, the user cannot estimate
the error rate at a given cutoff and this means that error analysis for
downstream analysis is difficult or impossible.
UTAX gives an estimated probability that the prediction is correct for each level (genus, family...).
RDP gives a bootstrap confidence value. The bootstrap value does not directly predict the error rate, but it does serve as a score which can be used to set of cutoff, which you cannot do with other prediction methods such as the default QIIME method (-m uclust), "BLAST-top-hit" or GAST.
We can compare the effectiveness of taxonomy classifiers and the predictive value of their confidence scores, if any, by making a graph which plots sensitivity against error rate. (For this analysis, the UTAX confidence estimate is treated as a score without asking whether the error rate it predicts is correct). If the plot shows that classifier A always has higher sensitivity at a given error rate than classifier B, then we are justified in saying that classifier A is better than classifier B. Sometimes, the curves intersect, in which case the claim is not so clear. However, in my experience, this rarely happens in the range of error rates that would be useful in practice -- with, say, an error rate of <5%, then it is usually possible to say that one classifier is definitively better than another.
Are scores comparable at different taxonomic levels?
We can now ask whether confidence scores are comparable between different levels. This is important for setting
a cutoff. For example, RDP recommends a cutoff at a bootstrap confidence level of
50% for short reads. Suppose this cutoff gives a 5% error rate at genus level.
(Actually, I measure the error rate at bootstrap>50 to be 40% on the V5
region!). Does this cutoff give
an error rate similar to 5% at family and above? If it does, then this justifies
using a single cutoff at all levels. If it does not, then the user should be
aware of this issue and might choose to set different cutoffs at different
taxonomic levels, say bootstrap>50 for genus but bootstrap>75 for family.
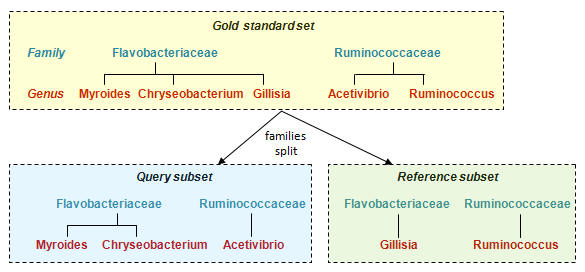
Example: Split at family level
Divide genera for each family into two random subsets, one for the Query subset
and one for the Reference subset. (Discard families with only one genus).
Family is always present in Query and Reference, genus is never present in both.
When trained on the reference subset, a taxonomy classifier could predict family level correctly for all query sequences because the family is known to be present in the training data. If the wrong family is predicted, this is a false positive error, if no family is predicted this is a false negative error.
The genus of a query sequence is never present in the
training data, so if a genus is predicted this is an
overclassification error.