See also
UCLUST algorithm
Recentering
Abundance sort
Sort order
UCLUST assumes that input sequences are sorted in an order such that
an appropriate centroid sequence is found before other members of its cluster.
The cluster_fast command automatically sorts by
decreasing length. This cannot be changed. The
cluster_smallmem command does not perform a sort, so it is the user's
responsibility to sort the input before clustering, e.g. by using the
sortbylength or
sortbysize commands. These implement the two most common sort orders,
summarized in the table below.
| Order |
Command |
Description |
|
Decreasing length |
sortbylength |
This order is most appropriate when input sequences
have large variations in length, e.g. because full-length sequences and
fragments are both present, as shown in the figure below. However, with a length sort, the longest sequence may be an
outlier. This can be addressed by recentering.
|
|
Decreasing abundance |
sortbysize |
See abundance sorting. |
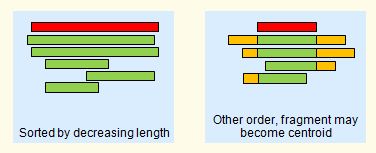
Multiple alignment of a cluster.
The centroid (representative) sequence is shown in red.
Fragments are poor centroids because member sequences may be
dissimilar in the regions that do not align to the fragment (orange).
|